Wenn ich mit KI-Coding arbeite, merke ich immer wieder denselben Unterschied: Ein schwacher Prompt klingt wie eine Bitte. Ein guter Prompt funktioniert wie ein kleines technisches Artefakt.
Das klingt zunächst pedantisch, ist aber praktisch. Ein Sprachmodell kann sehr viel implizit ergänzen. Genau das macht es nützlich. Genau das macht es aber auch riskant, wenn ich eigentlich reproduzierbare Ergebnisse will. Je weniger Struktur ich liefere, desto mehr muss das Modell raten: Ziel, Randbedingungen, Datenmodell, gewünschte Tiefe, Ausgabeformat, verbotene Wege und Abbruchkriterien.
Strukturierte Prompts und Prompt-Patterns sind deshalb keine Prompt-Magie. Sie sind eine Arbeitsdisziplin. Sie übersetzen vage Absicht in eine Form, die ein Modell konsistenter verarbeiten und ein Mensch leichter prüfen kann.
Warum Prompts überhaupt Struktur brauchen
Ein Prompt ist im KI-Coding selten nur eine Frage. Er ist eher ein temporärer Vertrag zwischen Mensch, Modell, Codebase und Werkzeugen. In ihm steht, welche Rolle das Modell einnehmen soll, welche Aufgabe wirklich gemeint ist, welcher Kontext zählt und welche Grenzen nicht verletzt werden dürfen.
Ohne diese Struktur entstehen typische Reibungsverluste: Das Modell optimiert eine Query, obwohl es das Schema nicht kennt. Es schlägt einen Index vor, obwohl Migrationen tabu sind. Es liefert Prosa, obwohl eine Pipeline JSON erwartet. Oder es refactort nebenbei Dateien, die gar nicht Teil der Aufgabe waren.
Meine Faustregel: Sobald ein KI-Ergebnis weiterverarbeitet, getestet, reviewed oder automatisiert genutzt werden soll, reicht ein freier Prompt nicht mehr. Dann braucht die Anfrage Struktur.
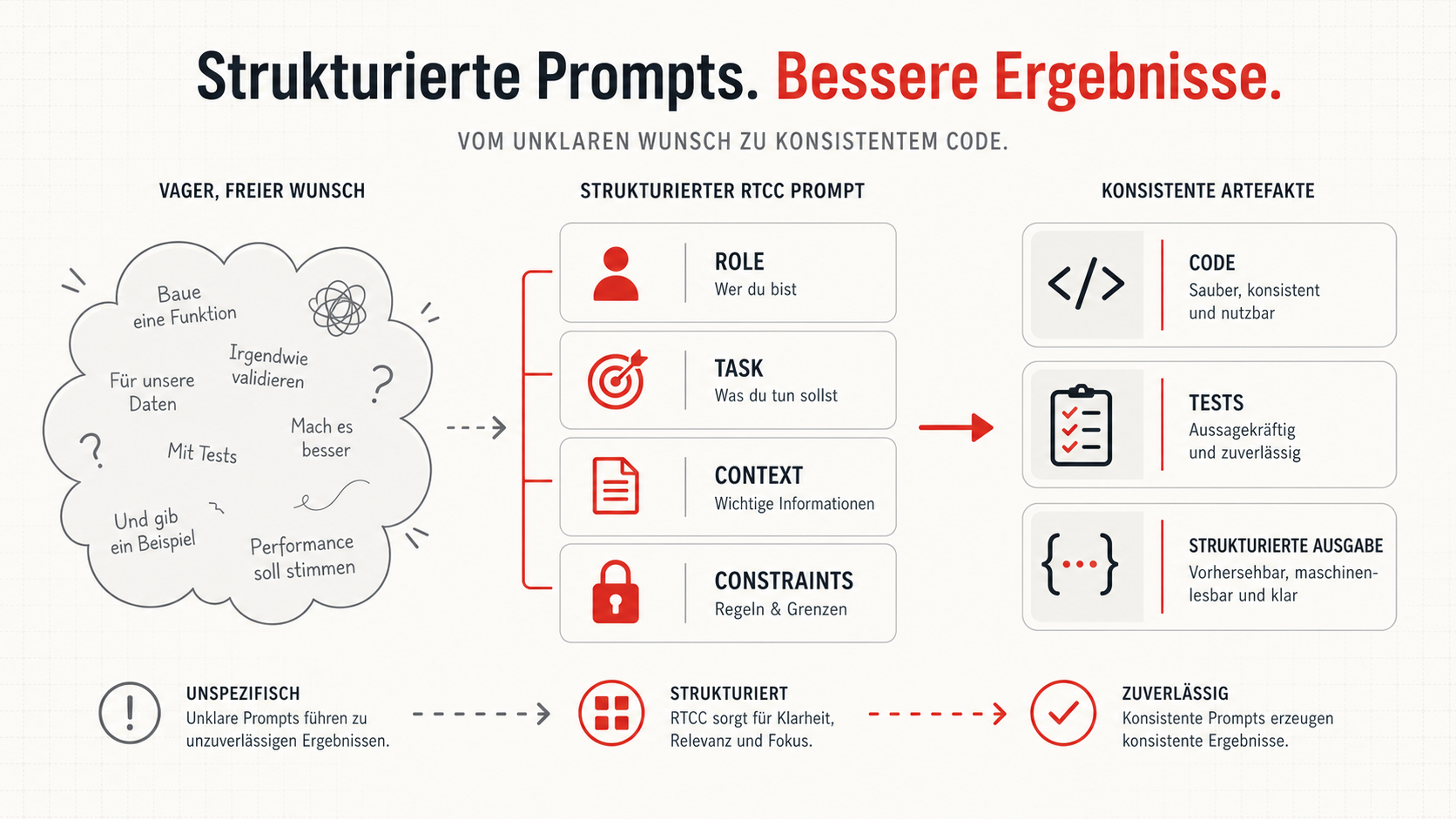
RTCC als Grundform: Role, Task, Context, Constraints
Das einfachste Muster, das ich praktisch fast überall einsetzen kann, ist RTCC: Role, Task, Context, Constraints. Es zwingt mich, vier Dinge zu trennen, die in schlechten Prompts oft durcheinanderlaufen.
RTCC ist keine starre Vorlage. Für sehr kleine Aufgaben reicht manchmal ein Satz. Aber sobald die Aufgabe mehrdeutig wird, verhindert diese Struktur, dass das Modell aus Bequemlichkeit eigene Annahmen nach vorne zieht.
Ein schwacher Prompt und eine bessere Variante
Der Unterschied wird sichtbar, wenn man einen typischen Alltags-Prompt auseinanderzieht.
„Mach die Abfrage schneller.“
„Optimiere diese Query mit Blick auf p95-Latenz unter 50 ms. Berücksichtige 80 Mio. Zeilen, aktuellen Indexstand, kein Partitioning und keine ungeprüften Schemaänderungen.“
Die schwache Variante zwingt das Modell zu Annahmen. Es weiß nicht, ob es SQL ändern darf, ob neue Indexe erlaubt sind, ob eine Migration möglich ist, welche Datenmenge relevant ist und woran Erfolg gemessen wird. Die strukturierte Variante begrenzt den Suchraum. Dadurch wird die Antwort nicht nur besser, sondern auch reviewbarer.
Role: Du bist Senior-Engineer mit Fokus auf Postgres 16 Performance. Task: Optimiere die unten gezeigte Query so, dass die p95-Latenz unter 50 ms bleibt. Context: - Tabelle orders hat ca. 80 Mio. Zeilen. - Aktuell existiert nur ein Index auf created_at. - Kein Partitioning. - Die Query wird im Checkout-Pfad verwendet. Constraints: - Kein Schemawechsel ohne explizite Markierung. - Erkläre die Wirkung jedes Indexvorschlags in einem Satz. - Liefere das Ergebnis als zwei Markdown-Codeblöcke: 1. SQL 2. EXPLAIN-Plan-Annotation
Prompt-Patterns: Bausteine für wiederkehrende Situationen
RTCC ist die Grundstruktur. Prompt-Patterns sind die ergänzenden Bausteine für spezielle Situationen. Ich denke dabei nicht an Tricks, sondern an wiederverwendbare Formen, die bestimmte Fehlerklassen reduzieren.
Warum ich Chain-of-Thought heute vorsichtig sehe
Ein älteres Pattern ist Chain-of-Thought: Das Modell soll seine Zwischenschritte sichtbar machen. Für Lern- oder Analysegespräche kann eine nachvollziehbare Begründung hilfreich sein. Für produktive Coding-Workflows ist aber wichtiger, dass das Modell prüfbare Ergebnisse liefert: Tests, Diffs, Annahmen, offene Fragen, Quellen, Schema-Validierung.
Moderne Reasoning-Modelle arbeiten intern ohnehin mit Zwischenüberlegungen. Ich fordere deshalb nicht pauschal „denk Schritt für Schritt“ an. Besser ist: „Nenne zuerst deine Annahmen“, „zeige die relevanten Risiken“, „liefere einen Testplan“ oder „prüfe die Ausgabe gegen dieses Schema“. Das führt zu verwertbarer Transparenz, ohne dass ich interne Denkprotokolle brauche.
Output-Schemas machen Prompts operationalisierbar
Der größte Qualitätssprung entsteht oft nicht durch schönere Formulierungen, sondern durch ein klares Ausgabeformat. Wenn eine KI-Antwort in einem Menschen-Review landet, reicht Markdown häufig. Wenn sie in ein Tool, eine Pipeline, ein Ticket-System oder einen weiteren Agenten geht, braucht sie ein Schema.
Ein Output-Schema beschreibt Felder, Typen, Pflichtangaben und erlaubte Werte. Dadurch kann ich automatisch prüfen, ob die Antwort nutzbar ist. Das ist ein entscheidender Unterschied: Ich bewerte nicht mehr nur, ob eine Antwort plausibel klingt, sondern ob sie formal weiterverarbeitet werden kann.
Praktischer Effekt: Ein Schema verschiebt Qualitätssicherung nach vorne. Das Modell bekommt nicht nur eine Aufgabe, sondern auch eine Zielstruktur. Fehler werden früher sichtbar.
Validierung gehört zum Prompt dazu
Strukturierte Prompts sind am stärksten, wenn sie nicht beim Prompt enden. Die Kette sollte so aussehen: Prompt strukturieren, Beispiele ergänzen, Schema fordern, Modell ausführen, Ausgabe validieren, nur bei Fehlern iterieren.
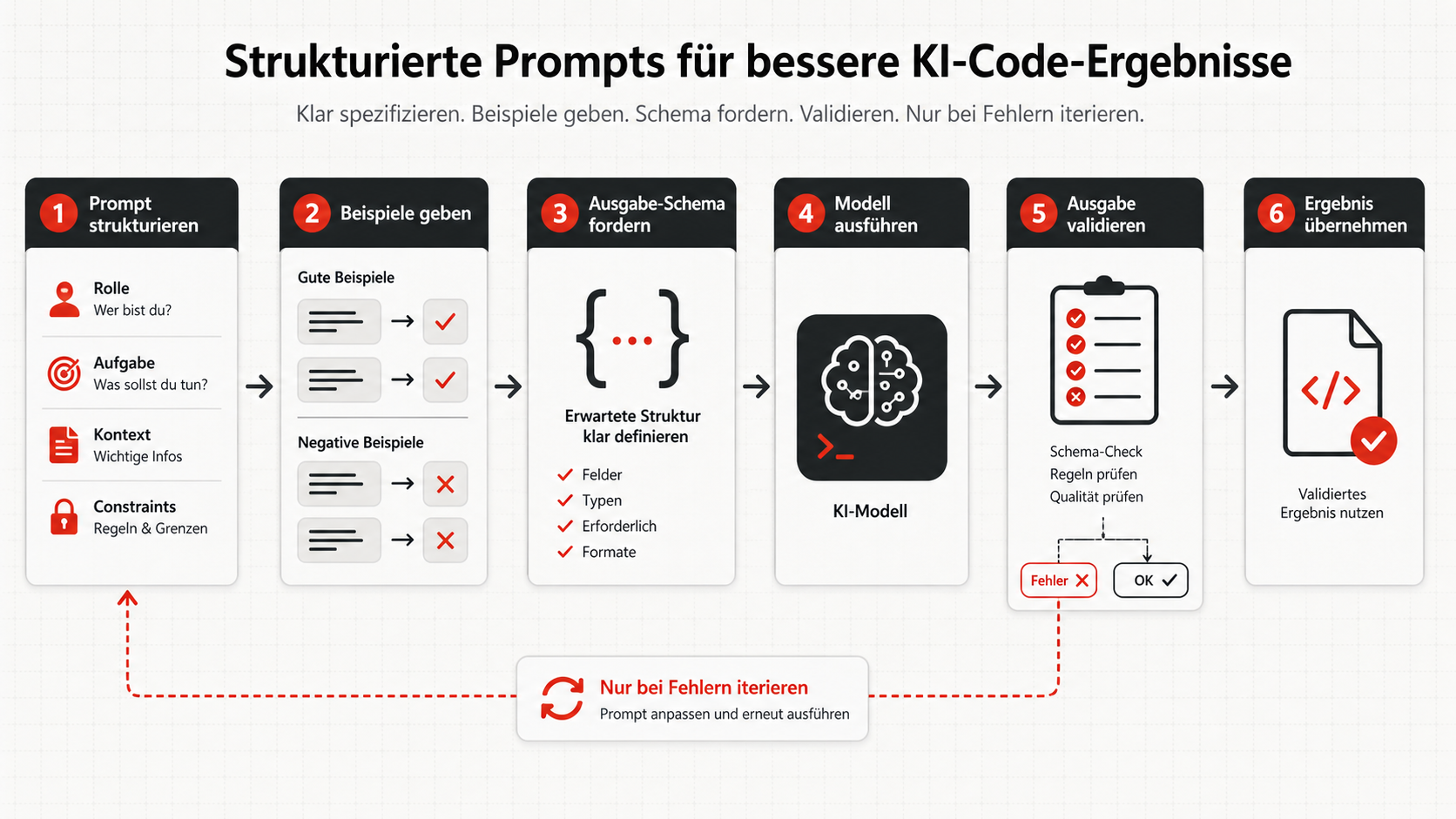
Das ist besonders wichtig bei Agenten. Ein Chat kann nachfragen. Ein Agent handelt. Je stärker ein Ergebnis downstream verwendet wird, desto weniger darf ich mich auf Bauchgefühl verlassen. Dann brauche ich Akzeptanzkriterien, Schemas, Tests oder explizite Review-Punkte.
Wie ich strukturierte Prompts im Alltag nutze
Ich beginne selten mit einer perfekten Vorlage. Meist schreibe ich erst die Aufgabe in einem Satz und zerlege sie dann: Was ist die Rolle? Was ist die eine konkrete Aufgabe? Welcher Kontext ist wirklich relevant? Welche Grenzen dürfen nicht überschritten werden? Wie soll das Ergebnis aussehen?
Wenn die Aufgabe wiederkehrt, mache ich daraus ein Pattern. Ein Review-Prompt bekommt eine feste Struktur. Ein Refactoring-Prompt bekommt negative Beispiele. Ein Recherche-Prompt bekommt Quellenanforderungen und Ausgabeformat. Ein Coding-Prompt bekommt Test- und Scope-Grenzen. So entsteht nach und nach eine kleine Bibliothek aus Prompts, die nicht spektakulär aussieht, aber zuverlässig Arbeit spart.
Der eigentliche Punkt: weniger Magie, mehr Engineering
Strukturierte Prompts sind kein Ersatz für Spezifikationen, Tests oder Architekturentscheidungen. Sie sind die Verbindungsschicht zwischen diesen Dingen und dem Modell. Je ernster ich KI-Coding nehme, desto weniger behandle ich Prompts als spontane Eingaben. Ich behandle sie als Artefakte: versionierbar, verbesserbar, überprüfbar.
Das verändert auch die Haltung. Ich frage nicht: „Wie bringe ich das Modell dazu, irgendwie die richtige Antwort zu geben?“ Ich frage: „Welche Struktur braucht die Aufgabe, damit ein Modell zuverlässig arbeiten und ich das Ergebnis sauber prüfen kann?“
Für mich ist genau das der Übergang von Prompting als Spielerei zu Prompting als Engineering-Praxis.