Der wichtigste Unterschied zwischen Chat und agentischem KI-Coding liegt nicht darin, dass der Agent „schlauer“ klingt. Er liegt darin, dass der Agent wiederholt mit Zustand, Werkzeugen und Ergebnissen arbeitet.
Ein Chat liefert eine Antwort. Ein Coding-Agent liest Dateien, bildet Hypothesen, ruft Tools auf, schreibt Code, startet Tests, beobachtet Fehler und entscheidet, ob der nächste Schritt noch sinnvoll ist. Diese wiederholte Struktur nenne ich agentische Schleife.
Sie ist der technische Kern vieler moderner Coding-Werkzeuge. Ob das Tool im Vordergrund freundlich als Assistent erscheint oder im Hintergrund autonom Aufgaben abarbeitet: Ohne Schleife bleibt es bei einer einzelnen Eingabe-Ausgabe-Beziehung. Mit Schleife entsteht ein Arbeitsprozess.
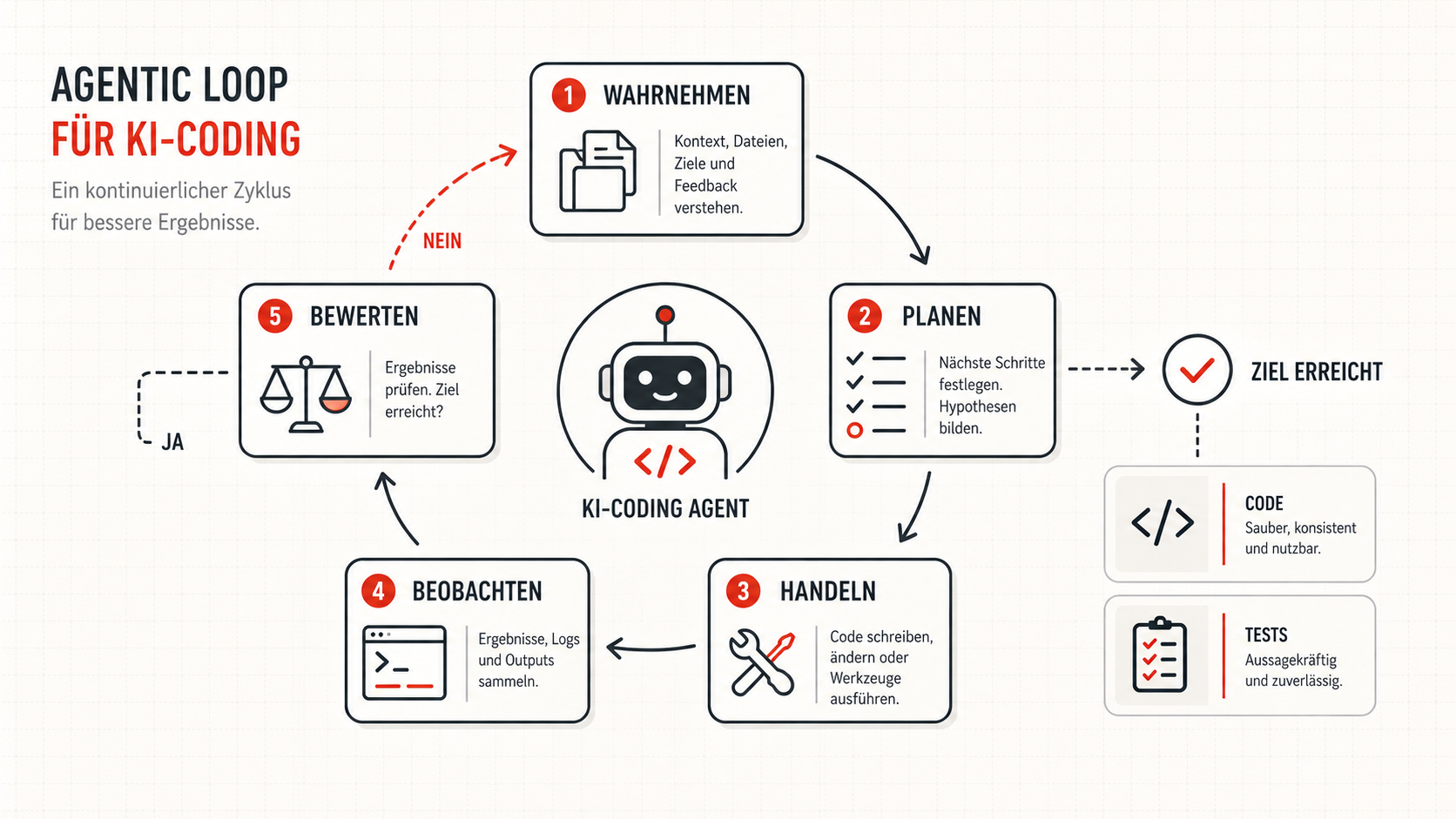
Was eine agentische Schleife ausmacht
Eine produktive Schleife besteht aus fünf Schritten. Die Reihenfolge ist wichtig, weil jeder Schritt den nächsten begrenzt. Wer direkt handelt, ohne wahrzunehmen, baut Zufall. Wer beobachtet, aber nicht bewertet, baut Endlosschleifen. Wer bewertet, aber keine klaren Abbruchkriterien hat, lässt den Agenten weiterarbeiten, obwohl das Ziel längst erreicht oder unerreichbar ist.
Diese Struktur ist tool-agnostisch. Sie taucht in Forschungsarbeiten wie ReAct auf, in Frameworks wie LangGraph oder AutoGen, und in praktischen Agent-SDKs mit Tools, Guardrails und Handoffs. Die konkreten APIs unterscheiden sich, aber das Muster bleibt: denken reicht nicht, handeln allein reicht auch nicht. Erst die Kopplung aus Handlung und Beobachtung macht den Agenten arbeitsfähig.
Warum Plan → Act → Verify nicht genügt
Viele beschreiben agentische Arbeit verkürzt als Plan → Act → Verify. Das ist hilfreich, aber für Coding zu grob. Im echten Arbeitsfluss ist „Verify“ nicht ein einzelner Schritt am Ende. Verifikation passiert ständig: nach einer Dateiinspektion, nach einer Hypothese, nach einem Tool-Aufruf, nach einem Testlauf, nach einem Diff.
Ich finde deshalb die feinere Schleife hilfreicher: Wahrnehmen, Planen, Handeln, Beobachten, Bewerten. Sie zwingt dazu, Tool-Outputs ernst zu nehmen. Ein Agent darf nicht einfach mit dem ursprünglichen Plan weitermachen, wenn die Beobachtung widerspricht. Er muss seine Hypothese anpassen.
Praktischer Maßstab: Ein guter Coding-Agent ist nicht der, der am längsten selbstständig weiterarbeitet. Ein guter Agent konvergiert: Er nähert sich dem Ziel mit möglichst kleinen, überprüfbaren Schritten.
Das Beispiel: ein fehlschlagender Test
Ein typischer Bugfix zeigt, warum diese Schleife so wichtig ist. Die Aufgabe klingt klein: Ein Test schlägt fehl. Ein schlechter Agent würde sofort Code ändern. Ein besserer Agent arbeitet in Schleifen.
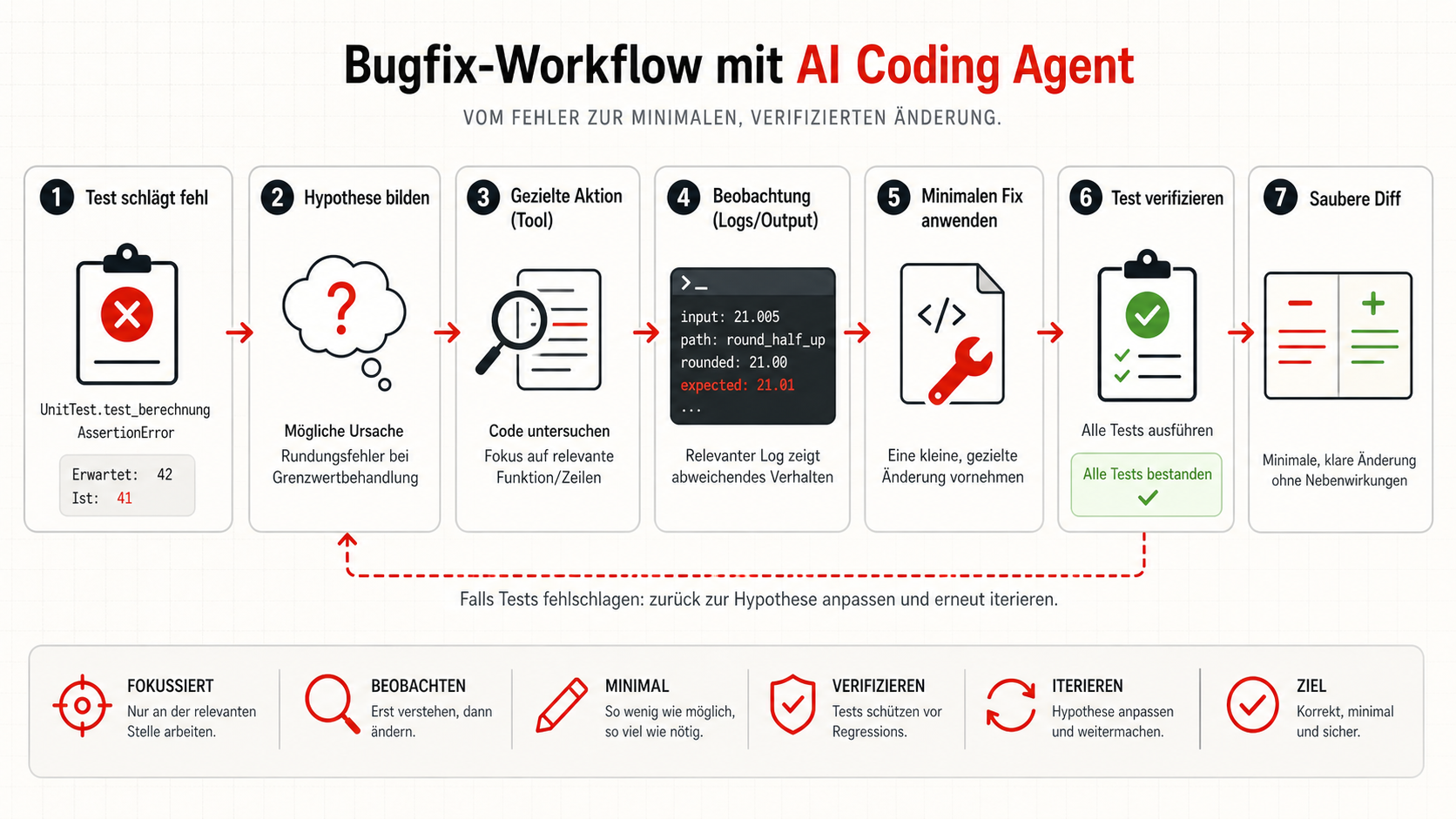
Der Ablauf ist unspektakulär, aber genau deshalb wertvoll. Der Agent liest zuerst die Testdatei und identifiziert den fehlschlagenden Assert. Dann formuliert er eine Hypothese, etwa „Off-by-One in der Pagination“. Danach liest er nicht das ganze Repository, sondern die relevante Funktion. Er führt einen fokussierten Test aus, beobachtet Log-Output oder Assertion-Differenz, ändert minimalen Code und lässt die Tests erneut laufen.
Entscheidend ist: Jede Runde muss Erkenntnis erzeugen. Wenn der Agent denselben Test fünfmal unverändert startet, arbeitet er nicht agentisch. Er wiederholt nur. Wenn er nach jeder Beobachtung seine Hypothese schärft, entsteht Fortschritt.
Abbruchkriterien sind kein Sicherheitszubehör
Der gefährlichste Agent ist nicht der, der zu wenig kann. Es ist der, der nicht merkt, wann er aufhören muss. Agentische Schleifen brauchen deshalb harte Abbruchkriterien. Sonst entstehen Endlosschleifen, Brute-Force-Retries, unnötige Diffs oder autonome Entscheidungen an Stellen, an denen ein Mensch gefragt werden muss.
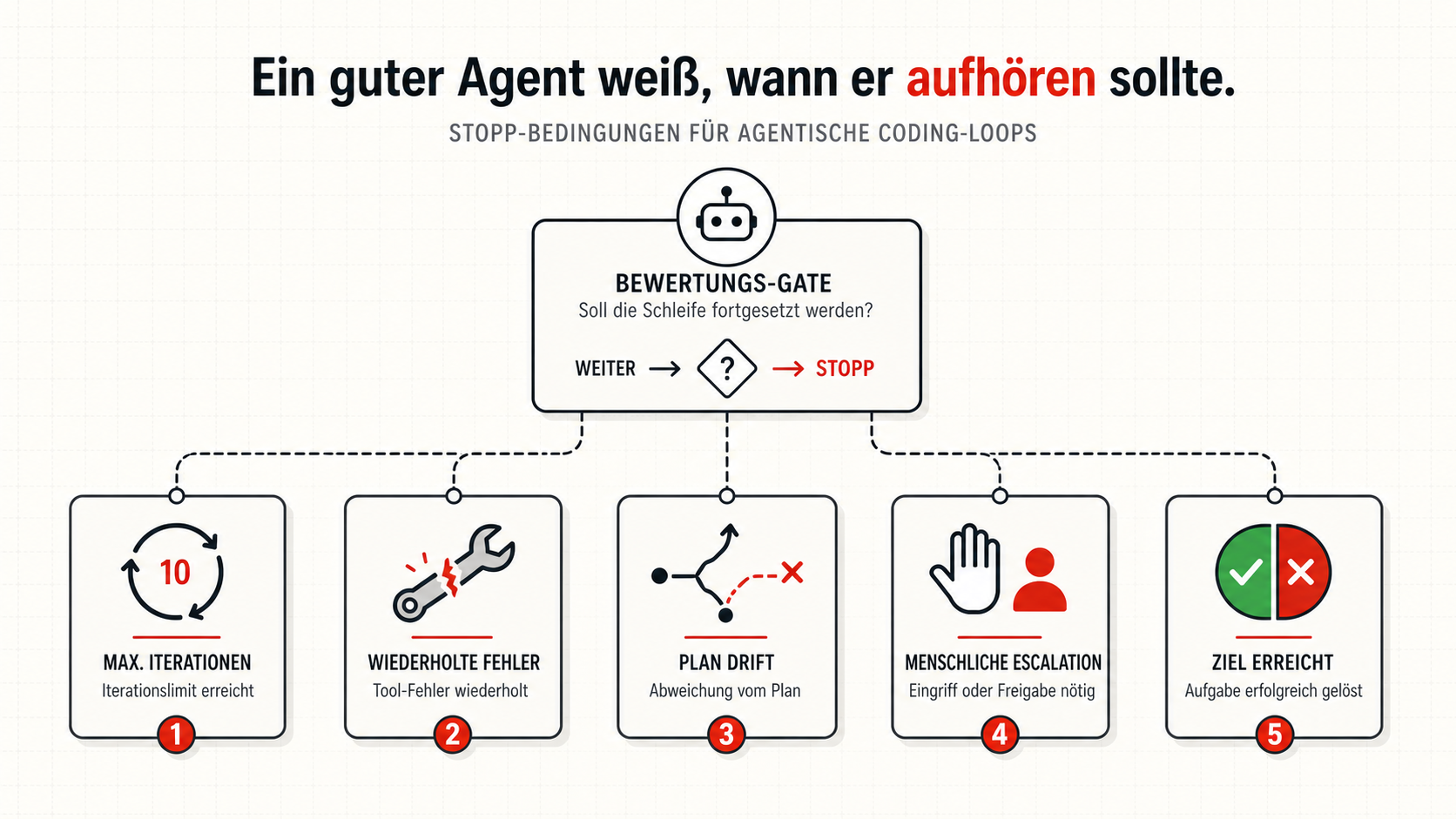
Was reife Implementierungen zusätzlich brauchen
Eine Schleife allein macht noch kein gutes System. Reife Implementierungen ergänzen Zustand, Berechtigungen, Observability und klare Grenzen. Der Agent muss wissen, was er sehen darf, welche Tools verfügbar sind, welche Aktionen Zustimmung brauchen, welche Zwischenergebnisse gespeichert werden und wie ein Lauf später nachvollzogen werden kann.
Das ist einer der Gründe, warum Frameworks und SDKs inzwischen so wichtig geworden sind. OpenAI Agents SDK, LangGraph oder AutoGen lösen nicht „Intelligenz“ als magischen Block. Sie geben Struktur für Tools, Übergaben, Workflows, Zustände und Kontrollen. Für mich ist das der Punkt: Agenten sind weniger ein Prompt-Thema als ein Prozess- und Architekturthema.
Die wichtigste Frage: konvergiert der Agent?
Bei agentischen Schleifen interessiert mich weniger, ob jeder einzelne Schritt beeindruckend wirkt. Mich interessiert, ob die Schleife konvergiert. Wird der Kontext kleiner und präziser? Werden Hypothesen besser? Werden Änderungen minimaler? Werden Tests gezielter? Werden Fehler weniger zufällig?
Wenn ja, arbeitet der Agent wie ein guter Entwickler im Debugging-Modus: beobachten, hypothesengetrieben handeln, prüfen, korrigieren. Wenn nein, produziert er Aktivität. Aktivität fühlt sich im Moment nach Fortschritt an, ist aber oft nur Lärm mit Tool-Zugriff.
Mein Qualitätskriterium: Eine agentische Schleife ist gelungen, wenn sie am Ende weniger offenen Raum hinterlässt als am Anfang: klarere Annahmen, kleinere Diffs, bestandene Tests und dokumentierte Restunsicherheit.
Was das für KI-Coding in der Praxis heißt
Wenn ich mit Coding-Agenten arbeite, versuche ich Aufgaben so zu formulieren, dass eine gute Schleife möglich wird. Dazu gehören ein klares Ziel, ein prüfbarer Erfolgszustand, relevante Kontextdateien, erlaubte Tools, Grenzen für Änderungen und eine Erwartung an den Abschluss.
Gute Prompts, Spezifikationen und Tests sind also nicht von agentischen Schleifen getrennt. Sie sind deren Futter und deren Bremse zugleich. Die Spec sagt, worauf hingearbeitet wird. Der Prompt setzt die Startbedingung. Die Tests und Akzeptanzkriterien entscheiden, ob die Schleife beendet werden darf.
Agentische Schleifen sind damit keine Zusatzfunktion moderner KI-Coding-Tools. Sie sind die Arbeitsform. Wer sie versteht, kann Agenten besser briefen, besser begrenzen und besser beurteilen.