Seit MCP in immer mehr KI-Tools auftaucht, klingt die Versuchung naheliegend: Für jedes interne System bauen wir einfach einen MCP-Server. Dann können Agenten überall andocken. Technisch ist das möglich. Architektonisch ist es nicht immer klug.
Das Model Context Protocol standardisiert, wie KI-Anwendungen externe Systeme, Datenquellen, Tools und wiederverwendbare Prompts nutzen können. Genau dadurch wird MCP spannend: Ein Server kann Fähigkeiten einmal bereitstellen, mehrere Hosts können sie verwenden. Aber diese Portabilität ist kein Freifahrtschein. Sie macht gute Integrationen wertvoller und schlechte Integrationen gefährlicher.
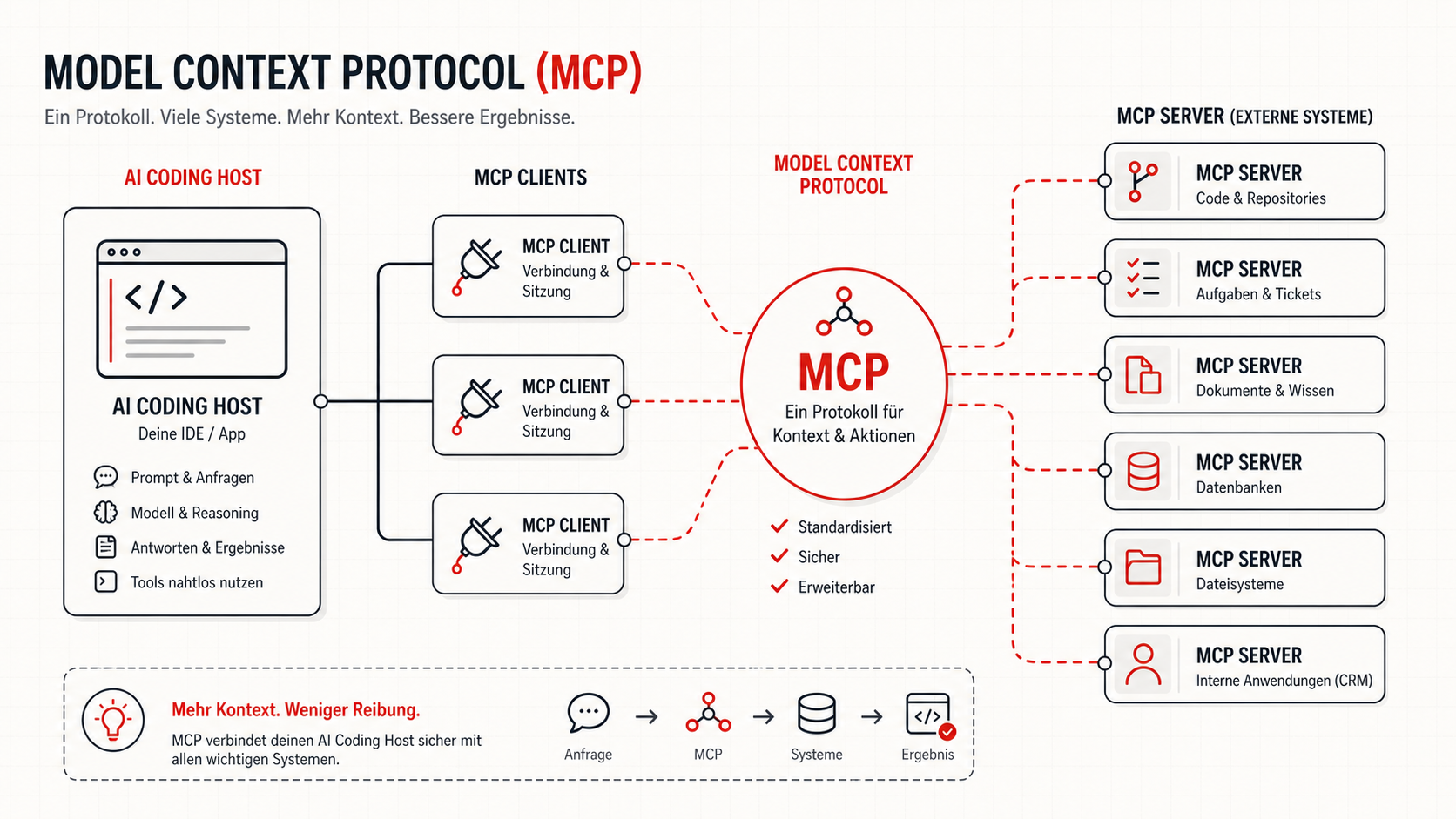
Die erste Frage ist nicht technisch
Ob ein eigener MCP-Server sinnvoll ist, entscheidet sich nicht daran, ob man ihn bauen kann. Die erste Frage ist: Gibt es eine stabile Domäne, die mehrere Agenten, Teams oder Arbeitsabläufe wiederverwenden sollen?
Wenn ein Team nur einmalig eine API ausliest, reicht oft ein bestehender Connector, ein Skript oder ein klar begrenztes internes Tool. Wenn aber mehrere KI-Hosts regelmäßig auf dieselbe Fachdomäne zugreifen sollen, wird MCP interessant. Dann entsteht aus einer Einzelintegration eine wiederverwendbare Integrationsschicht.
Meine Faustregel: Ein MCP-Server lohnt sich, wenn die Domäne langlebiger ist als das einzelne KI-Tool.
Wann ein eigener MCP-Server sinnvoll ist
Ich würde einen eigenen MCP-Server vor allem dann bauen, wenn mindestens einer dieser Gründe stark zutrifft.
Wann ich keinen eigenen Server bauen würde
Es gibt auch Fälle, in denen ein MCP-Server nach Architektur klingt, aber nur unnötige Oberfläche erzeugt. Nicht jede Datenquelle verdient sofort ein Protokollprodukt.
Der häufigste Fehler: API-Proxy statt Agentenwerkzeug
Der einfachste MCP-Server ist oft der schlechteste: Man nimmt eine bestehende REST-API und stellt jeden Endpunkt als Tool bereit. Das wirkt schnell produktiv, aber der Agent bekommt dadurch zu viele technische Hebel und zu wenig fachliche Absicht.
Ein gutes MCP-Tool sollte den Agenten nicht mit interner Systemmechanik beschäftigen. Es sollte eine sinnvolle Handlung anbieten. Nicht PATCH /customer/{id}, sondern zum Beispiel „Kundendatenänderung vorbereiten“, „Risiken der Änderung prüfen“ oder „Kontaktstatus zusammenfassen“. Der Unterschied ist groß: Der erste Ansatz exportiert Systemkomplexität. Der zweite Ansatz gestaltet Arbeitsfähigkeit.
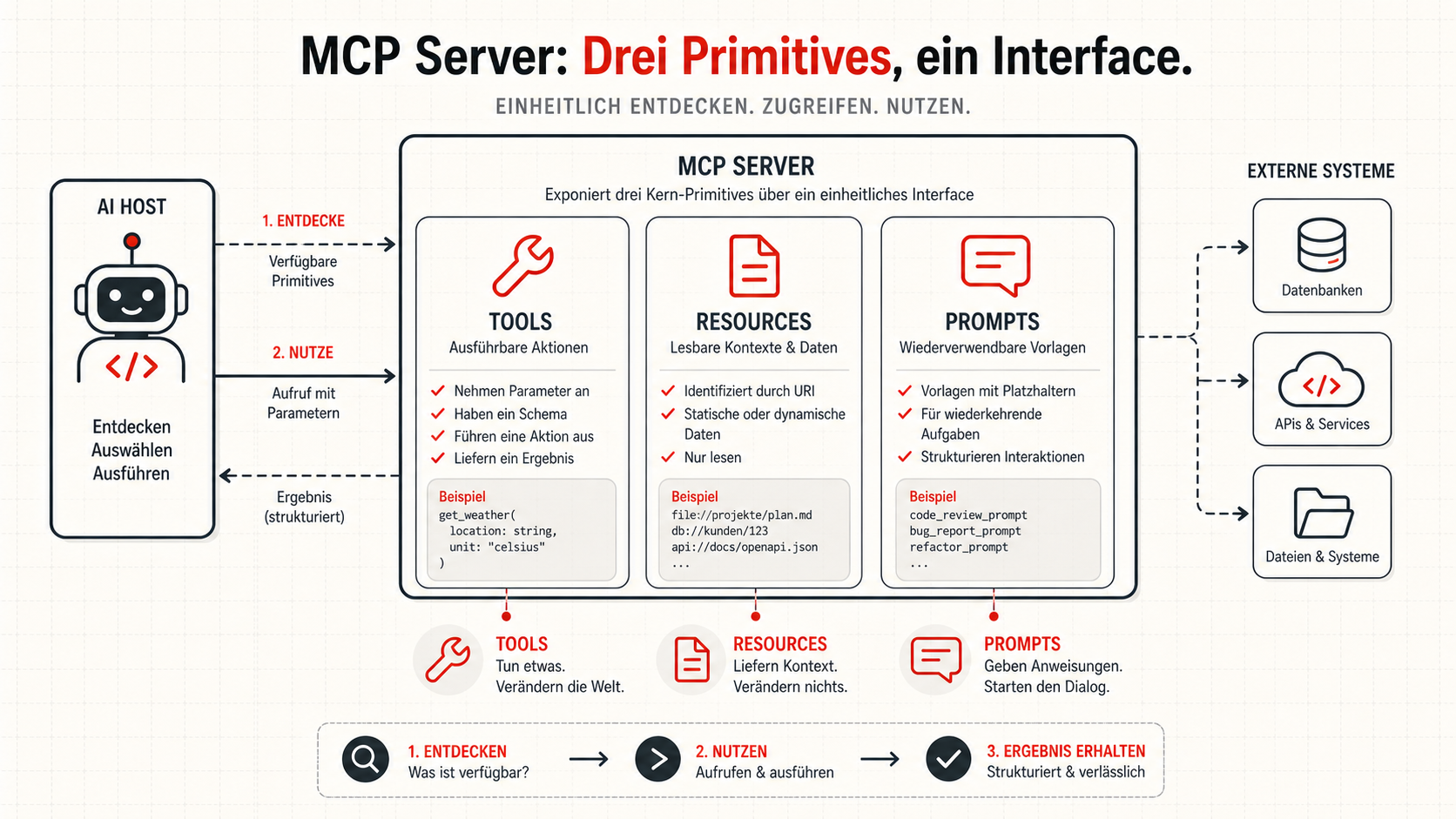
Die Sicherheitsfrage gehört an den Anfang
MCP macht Systeme für KI-Agenten erreichbar. Genau deshalb darf Sicherheit nicht nachträglich ergänzt werden. Sobald ein Server sensitive Daten oder Aktionen anbietet, braucht er klare Autorisierung, definierte Scopes, nachvollziehbare Logs und Schutz gegen gefährliche Tool-Kombinationen.
Besonders wichtig ist für mich die Unterscheidung zwischen lesen, vorbereiten und ausführen. Ein Agent darf vielleicht Kundendaten lesen, eine Änderung vorschlagen und eine Freigabe vorbereiten. Das heißt aber nicht, dass er dieselbe Änderung ohne Kontrolle schreiben darf. MCP gibt den Anschluss. Die Prozessgrenzen müssen wir selbst definieren.
Ein Entscheidungsmodell für die Praxis
Ich würde vor einem eigenen MCP-Server fünf Fragen beantworten. Wenn die Antworten unscharf bleiben, ist der Server wahrscheinlich noch zu früh.
Wo ich zuerst starten würde
Ich würde MCP-Server zuerst dort bauen, wo der Nutzen hoch und die Domäne klar begrenzt ist: interne Wissenssysteme, Entwicklerplattformen, Ticket- und Change-Prozesse, Build- und Deployment-Status oder fachliche Prüfservices. Das sind Bereiche, in denen Agenten regelmäßig Kontext brauchen und in denen kontrollierte Tool-Aufrufe echten Wert erzeugen.
Ich würde dagegen vorsichtig sein bei breit geöffneten CRUD-Servern, direkten Datenbankaktionen oder Integrationen, die nur existieren, weil ein Tool gerade MCP unterstützt. Der Standard ist kein Grund, jede Schnittstelle sofort neu zu verpacken. Er ist ein Grund, wiederkehrende Integrationen sauberer zu bauen.
Fazit
Ein eigener MCP-Server lohnt sich, wenn er eine stabile, wiederverwendbare und kontrollbedürftige Domäne kapselt. Dann wird er zu einem wertvollen Architekturbaustein: portabel zwischen Hosts, fachlich enger als eine Roh-API und besser kontrollierbar als verstreute Einzelintegrationen.
Wenn dagegen Wiederverwendung, Ownership, Berechtigungen oder Tool-Design unklar sind, würde ich warten. Gute Agentenarchitektur entsteht nicht dadurch, dass jede API ein MCP-Label bekommt. Sie entsteht, wenn wir entscheiden, welche Fähigkeiten Agenten wirklich brauchen und unter welchen Grenzen sie diese Fähigkeiten nutzen dürfen.